1 Losparse
简介
| 名称 | LoSparse: Structured Compression of Large LanguageModels based on Low-Rank and Sparse Approximation |
|---|---|
| 期刊 | ICML |
| 发表时间 | 2023.7 |
| 代码 | yxli2123/LoSparse (github.com) |
| 压缩技术 | 低秩近似、结构剪枝 |
方法
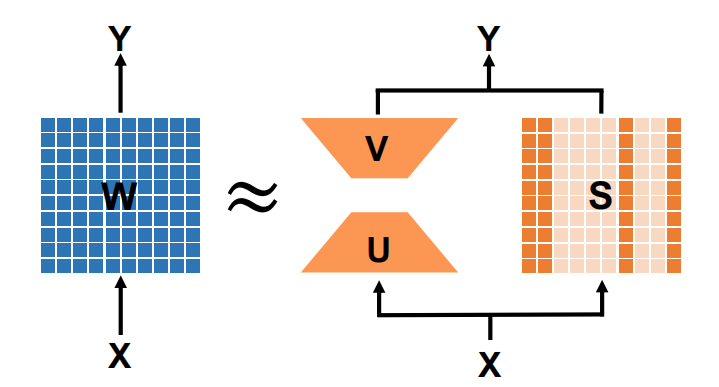
将权重近似为(将这种分解应用于模型的每个权重矩阵):
重要性评分公式方法:
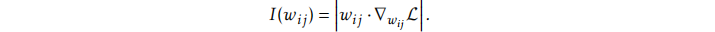

i
剪枝采用迭代剪枝,在迭代过程中S的重要性评估不稳定,原文采用平滑+大batchsize。由于样本造成的不稳定,这里可以想一个办法。要不让样本更稳定,要不更换一个重要性评估方法。
初始化$U^0$和$V^0$会丢失很多知识,在文中,矩阵分解占比仅有1-5%,其余都是S的占比。如果在不增加UV的占比情况下提高他的知识,是否可以去除更多的S?考虑加权分解。先加权分解UV,在迭代剪枝。最后微调?
实验
评估任务:natural language understanding (NLU)、question answering (QA)、natural language generation (NLG)
压缩模型:DeBERTaV3-base、, BERT-base、BART-large
Baselines: Full fine-tuning 、Movement pruning、Iterative pruning (ITP)
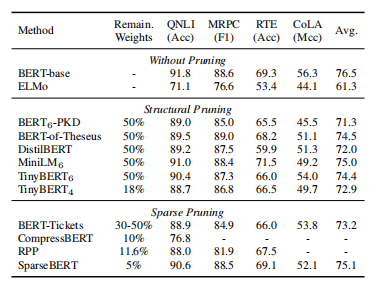
Natural Language Understanding
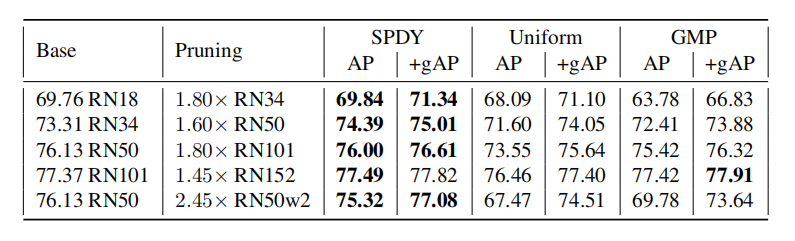
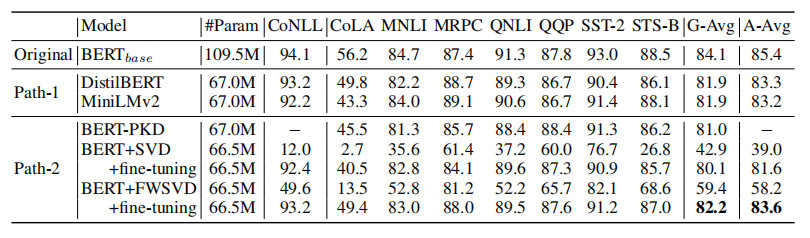
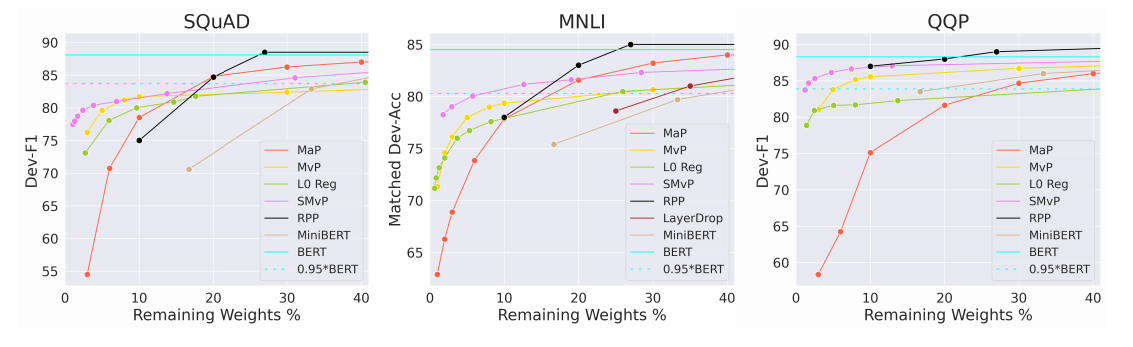
在通用语言理解评估(GLUE)基准上修剪DeBERTaV3-base模型:
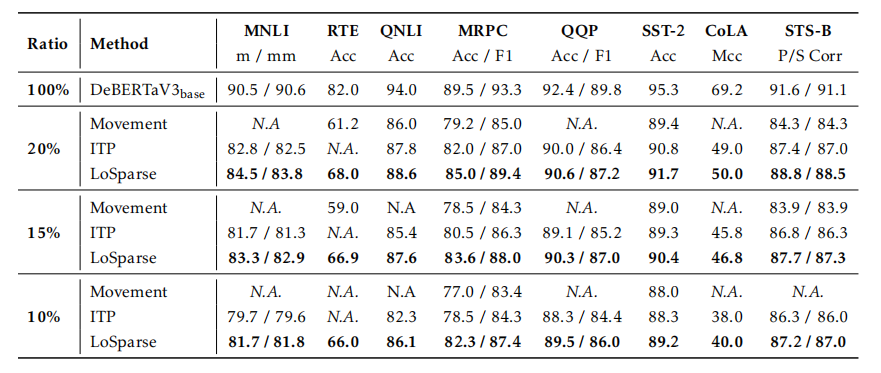
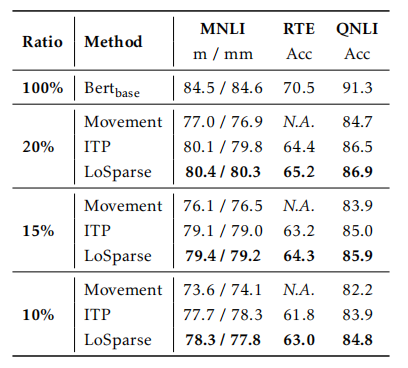
修剪bert:
Question Answering
在SQuADv1.1上压缩了DeBERTaV3-base和BERT-base:
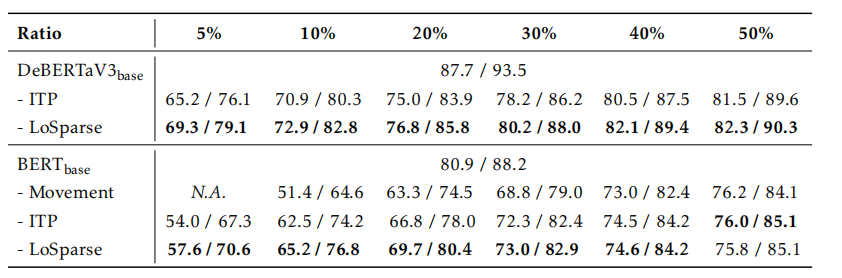
Natural Language Generation
在XSum和CNN/DailyMail数据集上压缩BART-large:
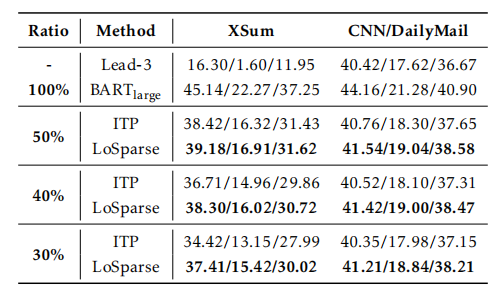
2 LoRAPrune
简介
| 名称 | PRUNING MEETS LOW-RANK PARAMETER-EFFICIENT FINE-TUNING |
|---|---|
| 期刊 | |
| 发表时间 | 2023.3 |
| 代码 | 无 |
| 压缩技术 | 剪枝 SOTA |
方法
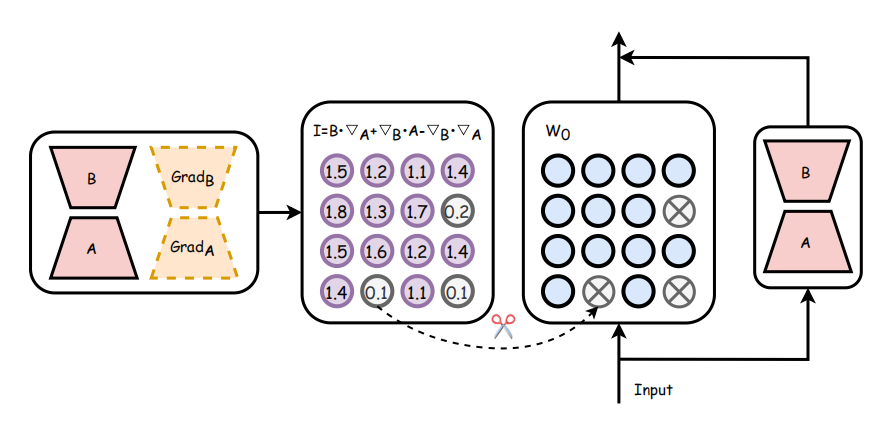
插入lora,用lora的梯度代替权重的梯度。
使用一阶泰勒展开式来近似的重要性过于复杂,因此改为使用BA的梯度:
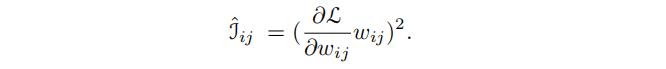
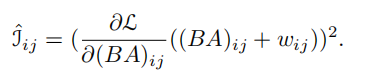
BA梯度仍然复杂,因此继续近似:
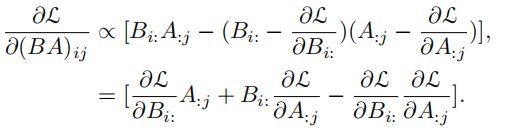

i
用lora代替w进行计算。前百分之10与后百分之30只涉及参数更新。修剪过程采用“修剪-微调-修剪方法”。
实验
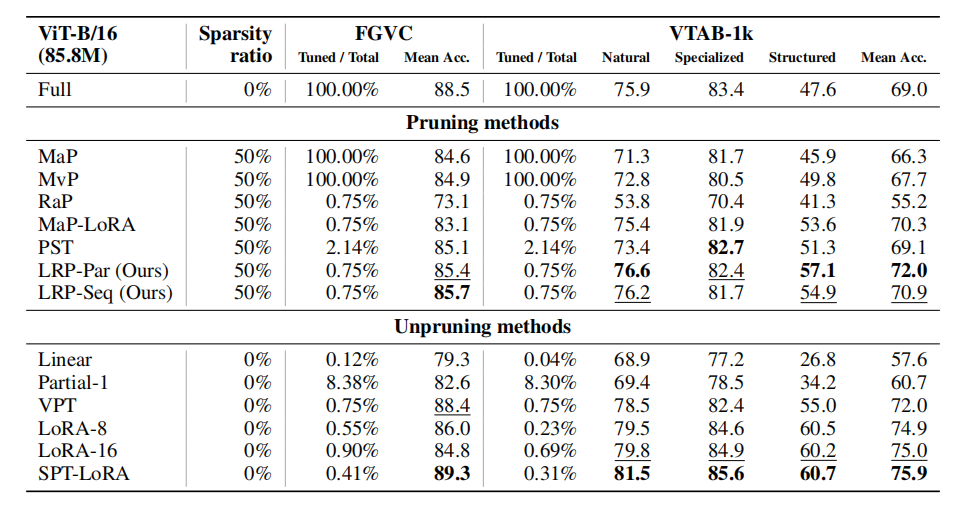
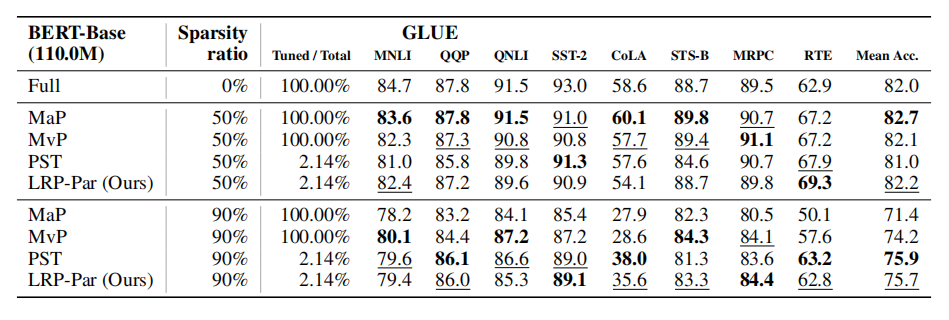
任务:VTB-1k(19 个图像分类数据集)、FGVC(CUB-200-2011、NABirds、Oxford Flowers、Stanford Cars 和 Stanford Dogs)、GLUE(CoLA、SST-2、MRPC、STS-B、QQP、MNLI、QNLI、RTE 等任务)
对于CV任务采用ViT-B/16模型,对于NLP任务采用 BERT-base模型(RTX3090)
对比:幅值修剪(MaP)、带LoRA的幅值修剪(MaP-LoRA)、运动修剪(MvP)、随机修剪(RaP)、参数高效稀疏性(PST)
结果(微调和剪枝过程结合在一起是高效):
3 PruneOFA
简介
| 名称 | Prune Once for All: Sparse Pre-Trained Language Models |
|---|---|
| 期刊 | |
| 发表时间 | 2021.11 |
| 代码 | |
| 压缩技术 | 非结构化剪枝、蒸馏 |
方法
采用渐进幅度修剪:
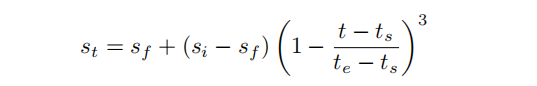
流程:
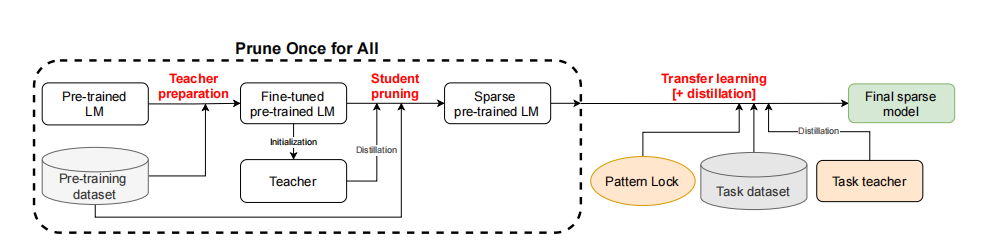
提出模式锁的方法,它可以防止在训练模型时改变模型中发现的零
实验
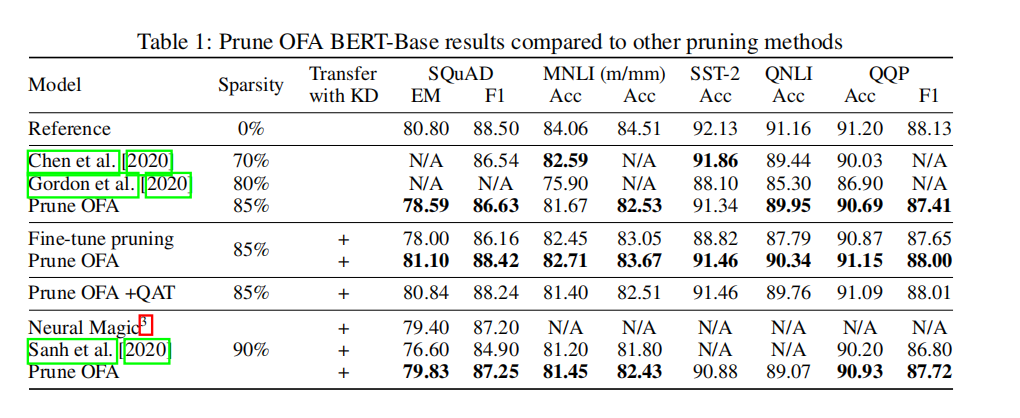
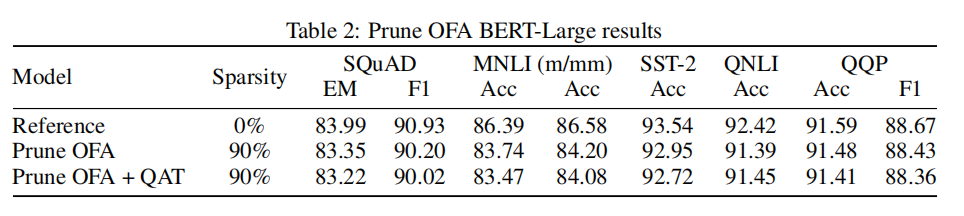
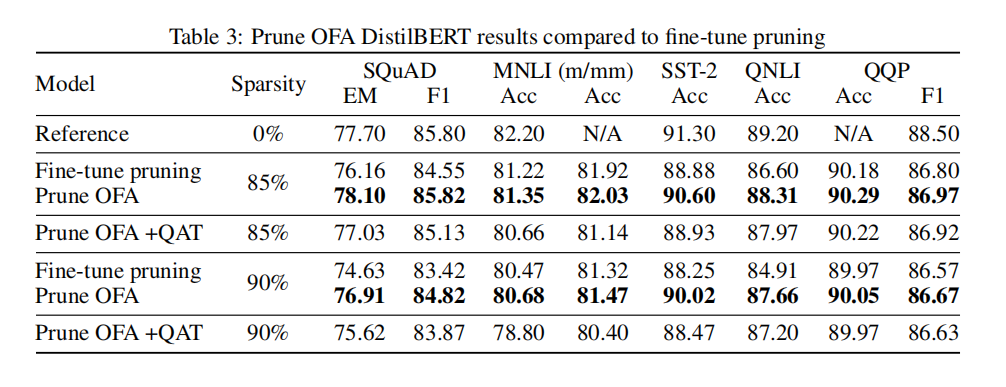
模型:BERT-Base, BERT-Large and DistilBERT
4 oBert
简介
| 名称 | The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models |
|---|---|
| 期刊 | EMNLP |
| 发表时间 | 2022.10 |
| 代码 | sparseml/research/optimal_BERT_surgeon_oBERT at main · neuralmagic/sparseml (github.com) |
| 压缩技术 | 非结构化剪枝 |
方法
采用二阶Hassian矩阵近似重要性进行剪枝:
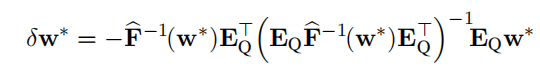
采用经验fisher矩阵近似hassian矩阵:
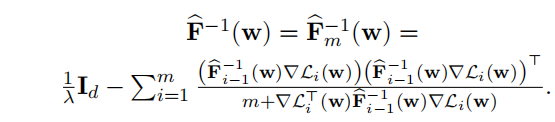
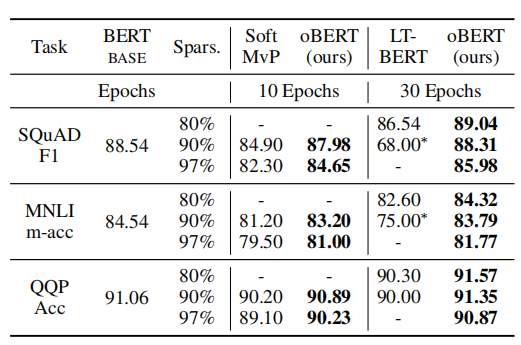
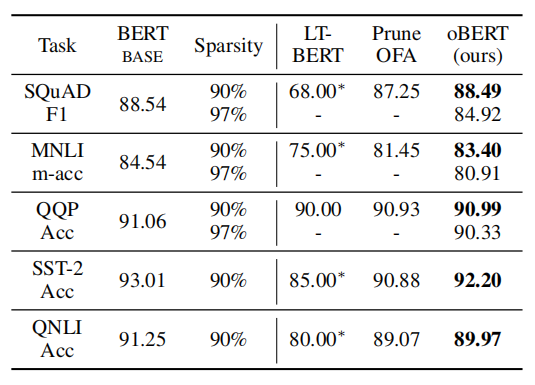
实验
比较方法:Movement Pruning (MvP)、Lottery Ticket (LT-BERT)
5 FLOP
简介
| 名称 | Structured Pruning of Large Language Models |
|---|---|
| 期刊 | EMNLP |
| 发表时间 | 2021.5 |
| 代码 | sparseml/research/optimal_BERT_surgeon_oBERT at main · neuralmagic/sparseml (github.com) |
| 压缩技术 | 低秩近似、结构化剪枝 |
方法
端到端的训练方法,优化目标:
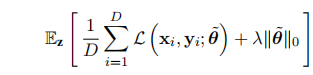
重新参数化技巧:
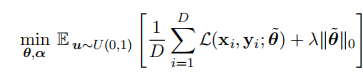
利用低秩因子分解的权重矩阵参数化方法:
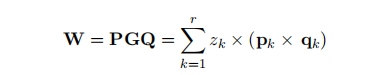
增强拉格朗日方法:
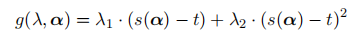
优化的最终目标:
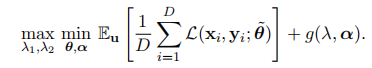
实验
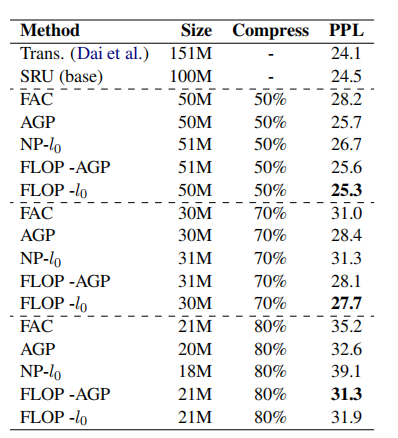
6 FWSVD
简介
| 名称 | LANGUAGE MODEL COMPRESSION WITH WEIGHTED LOW-RANK FACTORIZATION |
|---|---|
| 期刊 | ICLR |
| 发表时间 | 2022.6 |
| 代码 | https://github.com/RahulSChand/Weighted-low-rank-factorization-Pytorch |
| 压缩技术 | 加权分解 |
方法
矩阵分解:
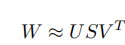
Fisher信息:
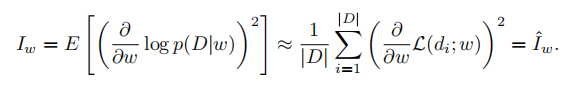
费雪加权低秩近似:
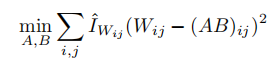
i
微调lora(保留增量梯度)->计算重要性->加权分解SVD->W=BA+S剪枝(剪枝S,微调BA)
W每一行相同的权重,否则没有闭环解?如何改进。
单词嵌入层(非负矩阵分解,考虑人脸识别和数字分解)
实验
压缩路径:
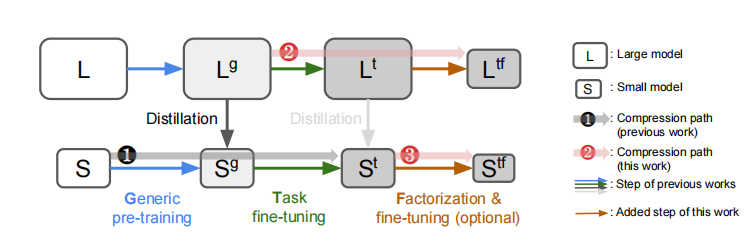
7 LLM-Pruner
简介
| 名称 | LLM-Pruner: On the Structural Pruning of Large Language Models |
|---|---|
| 期刊 | NeurlPS |
| 发表时间 | 2023.9 |
| 代码 | https://github.com/horseee/LLM-Pruner |
| 压缩技术 | 结构剪枝+LoRA微调 |
方法
发现依赖结构->评估重要性(采用二阶导数)->微调恢复
实验
无baselines
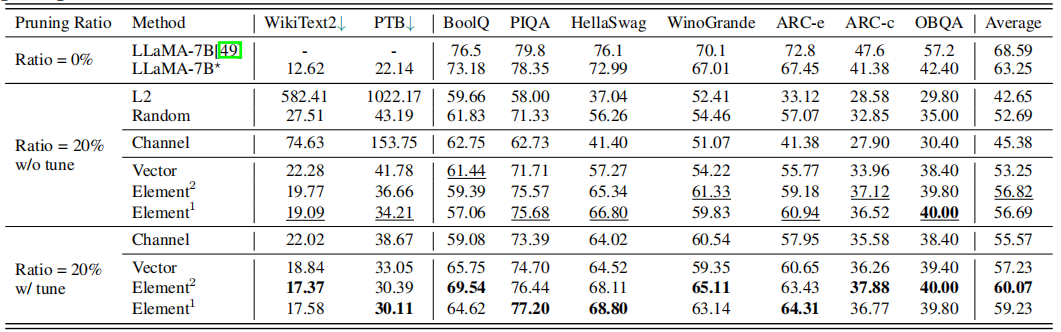
8 SHEARED LLAMA
简介
| 名称 | SHEARED LLAMA: ACCELERATING LANGUAGE MODEL PRE-TRAINING VIA STRUCTURED PRUNING |
|---|---|
| 期刊 | |
| 发表时间 | 2023.10 |
| 代码 | https://github.com/horseee/LLM-Pruner |
| 压缩技术 | 结构剪枝+动态批量加载 |
方法
微调对于结构剪枝至关重要
端到端剪枝
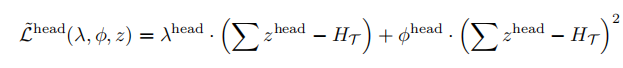
根据训练数据比例动态加载训练数据
实验
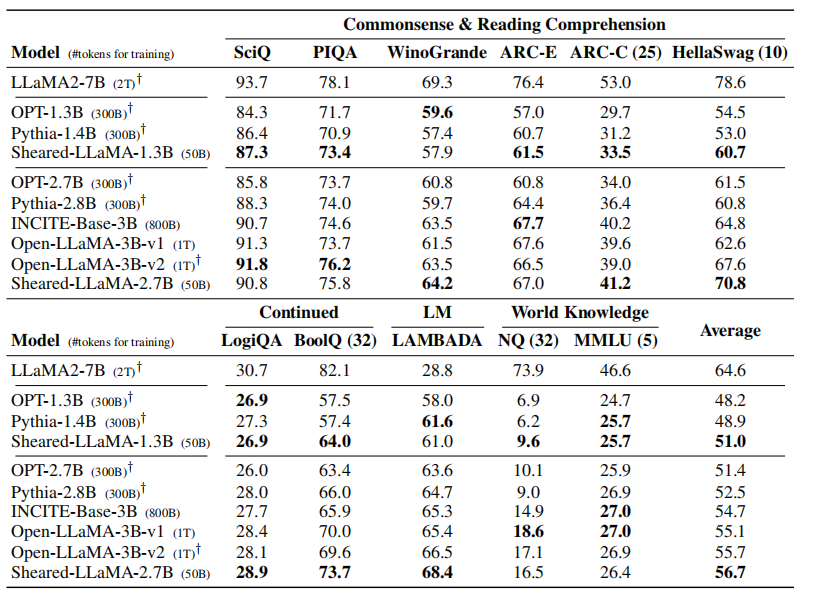
9 ZipLM
简介
| 名称 | ZipLM: Hardware-Aware Structured Pruning of Language Models |
|---|---|
| 期刊 | |
| 发表时间 | 2023.2 |
| 代码 | |
| 压缩技术 | 结构剪枝+知识蒸馏、逐层剪枝 |
方法
一次剪枝一个结构来解决相关性问题。
权重更新,二阶导数近似:
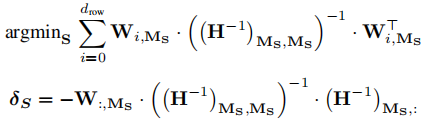
蒸馏:
实验
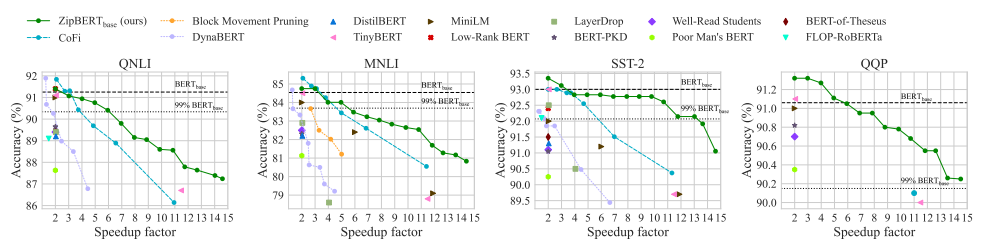
10 Matrix Decomposition
简介
| 名称 | Compressing Pre-trained Language Models by Matrix Decomposition |
|---|---|
| 期刊 | AACl |
| 发表时间 | 2021 |
| 代码 | https://github.com/kene111/matrix-decomposition |
| 压缩技术 | 低秩分解+蒸馏 |
方法
通过SVD分解
知识蒸馏,训练损失由三部分构成:
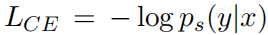
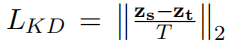
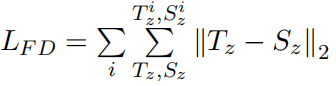
基础模型(微调模型)用于分解和作为教师模型
实验
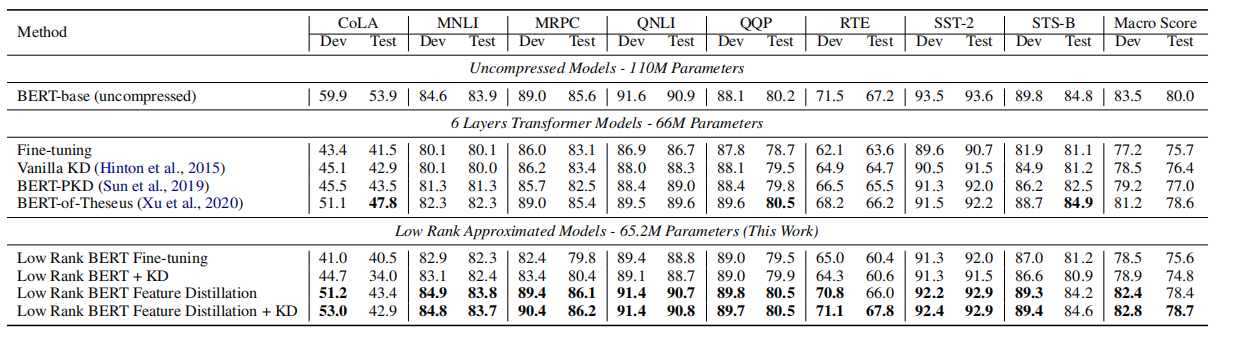
11 Movement Pruning
简介
| 名称 | Movement Pruning:Adaptive Sparsity by Fine-Tuning |
|---|---|
| 期刊 | NeurIPS |
| 发表时间 | 2020 |
| 代码 | |
| 压缩技术 | 移动剪枝 |
方法
考虑到权重值在迁移学习中不是从头开始的,传统的基于幅度的剪枝可能无法充分适应新任务的需求,因为他们的修剪决策是基于原始模型的权重值。公式推导:
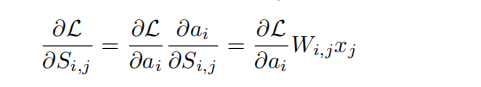
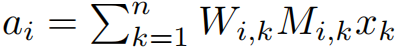
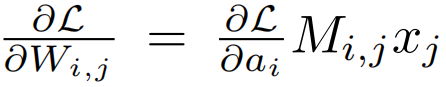
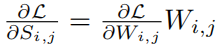
从公式可以看出,当W远离0点是,重要性S变大。于是修剪那些逐渐靠近0的权重而幅度修剪的方法修剪离0近的值。
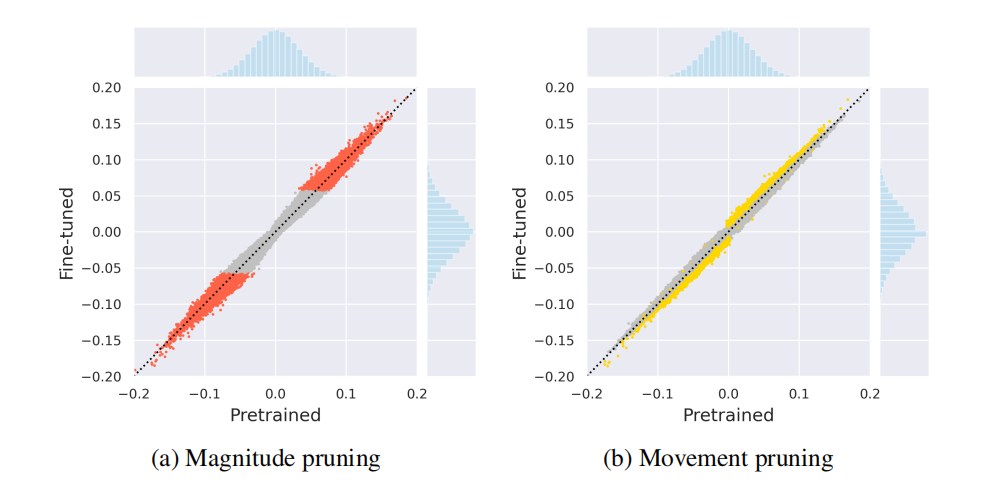
实验
12 ITP
简介
| 名称 | Importance Estimation for Neural Network Pruning |
|---|---|
| 期刊 | CVPR |
| 发表时间 | 2019 |
| 代码 | https://github.com/NVlabs/Taylor_pruning*.* |
| 压缩技术 | 迭代剪枝、一阶二阶近似 |
方法
计算精确的重要性对于大型网络来说是及其昂贵的,然后采用一阶或二阶近似的方法评估重要性。
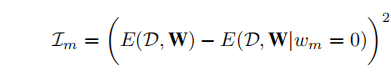
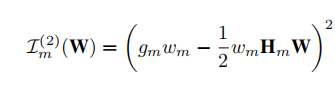
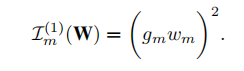
以一个训练过的网络作为输入,并在一个具有较小学习率的迭代微调过程中对其进行剪枝。在每个时期内,都要重复以下步骤:
- 对于每个小批处理,我们计算参数梯度,并通过梯度下降来更新网络权值。我们还计算了每个神经元(或滤波器)的重要性
- 在预定义的小批之后,我们将每个神经元(或过滤器)的重要性分数取为小批的平均值,并去除N个重要性分数最小的神经元
实验
在LSTM上做的实验。
13 HMD
简介
| 名称 | Rank and run-time aware compression of NLP Applications |
|---|---|
| 期刊 | EMNLP |
| 发表时间 | 2020 |
| 代码 | |
| 压缩技术 | 混合低秩压缩 |
方法
实验
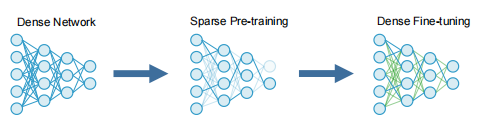
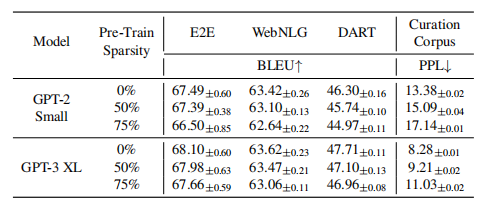
14 SPDF
简介
| 名称 | SPDF: Sparse Pre-training and Dense Fine-tuning for Large Language Models |
|---|---|
| 期刊 | EMNLP |
| 发表时间 | 2023 |
| 代码 | |
| 压缩技术 | 剪枝之后恢复剪枝 |
方法
首先,我们预先训练一个稀疏GPT模型,以减少计算训练的流量。然后,在微调阶段,我们强化GPT模型,允许零权值学习并增加建模能力,以更准确地学习下游任务。采用随机修剪,均匀稀疏的方法
三个假设:
- 在llm的训练前阶段,可以使用高程度的权重稀疏度,同时通过密集的微调来保持下游的精度。
- 稀疏预训练模型的性能与下游任务中数据集的大小和难度相关。
- 当我们增加语言模型的规模时,更大的模型在训练前变得更容易接受更高水平的稀疏性。
实验
15 A Fast Post-Training Pruning Framework forTransformers
简介
| 名称 | A Fast Post-Training Pruning Framework for Transformers |
|---|---|
| 期刊 | NeurIPS |
| 发表时间 | 2022 |
| 代码 | https://github.com/WoosukKwon/retraining-free-pruning |
| 压缩技术 | 训练后采用20K数据三分钟剪枝 |
笔记
- 剪枝是降低变压器模型巨大推理成本的一种有效方法。然而,之前关于修剪变压器的工作需要重新训练模型
- 虽然结构化剪枝方法可以实现高压缩率和加速,但它们通常很难在实践中使用。其中一个原因是在修剪期间或修剪后额外训练的计算成本很高,另一个原因是剪枝管道的高度复杂性,其中每个剪枝阶段通常需要重写训练代码,并引入额外的超参数来进行调优。
方法
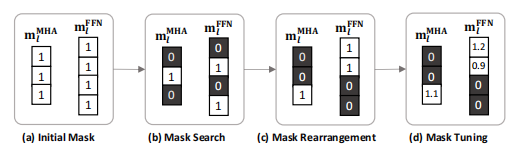
定义问题:
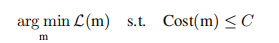
二阶近似:
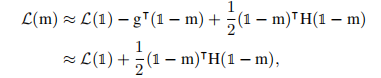
海森近似:
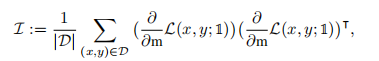
掩码搜索:
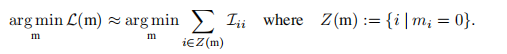

掩码重排:
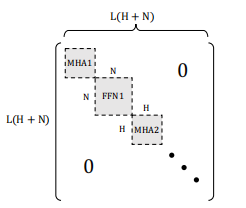
虽然它简化了问题,但仅使用对角线假设可能无法找到最佳的解决方案,因为它没有考虑到不同掩模变量之间的相互作用。例如,如果在一个图层中有两个注意头发挥着相似的作用,那么只修剪其中一个可能不会影响模型的准确性。然而,当它们两者都被修剪时,模型的精度可能会显著降低。这种交互作用被费雪信息矩阵的非对角元素捕获,在前一阶段被忽略。因此,我们可以通过使用对Fisher矩阵的块对角近似来更好地考虑剪枝问题中的相互作用,其中一个块对应于一个MHA层或一个FFN层,如下图所示。
用贪婪算法近似地解决这个问题。在将掩模初始化即热启动)后,为每一轮选择一个具有最高Fisher信息的修剪头(或过滤器),并与当前掩模中的一个未修剪头(或过滤器)交换:
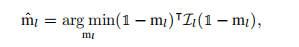
掩码微调:
非零变量被调优到任何真实值,这样修剪后的模型就可以恢复其精度。通过线性最小二乘法进行分层重建。我们调整掩模变量以使最小化层重构误差,。从第一层到最后一层,我们用修剪模型中剩余的头/滤波器重建原始模型的输出激活。正式形式如下:
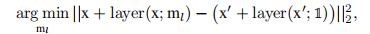
实验
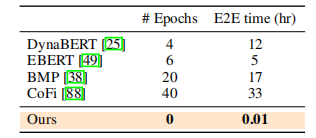
16 随机森林预测剪枝架构
简介
| 名称 | PRUNING LARGE LANGUAGE MODELS VIA ACCURACY PREDICTOR |
|---|---|
| 期刊 | |
| 发表时间 | 2023 |
| 代码 | |
| 压缩技术 | 建立预测器预测剪枝体系结构 |
笔记
- 目前,llm压缩的一些工作主要集中在模型量化上
- 注意层的重要性远高于MLP:
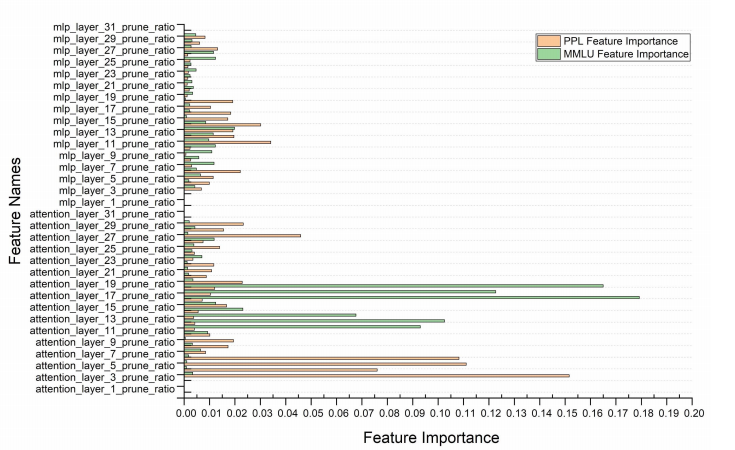
方法
构建架构-精度对:

权重重要性评估:
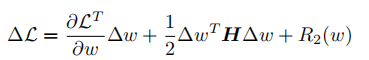
建立随机森林模型。
QLoRA微调恢复。
实验
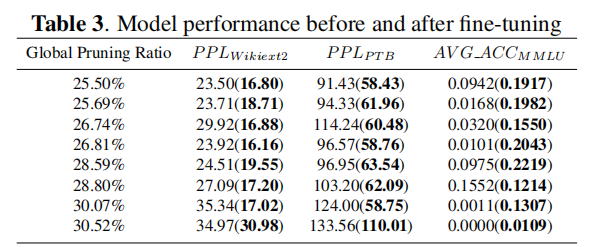
17 Wanda
简介
| 名称 | A SIMPLE AND EFFECTIVE PRUNING APPROACH FOR LARGE LANGUAGE MODELS |
|---|---|
| 期刊 | |
| 发表时间 | 2023 |
| 代码 | locuslab/wanda: A simple and effective LLM pruning approach. (github.com) |
| 压缩技术 | 一次剪枝,不需要再训练或重量更新 |
笔记
- 由于最近在llm中出现的大幅度特征的观察,我们的方法在每个输出的基础上,将最小幅度的权重乘以相应的输入激活。
- 到目前为止,许多显著的进展都集中在模型量化上,这是一个将参数被量化为更低的位级表示的过程
- 幅度修剪(Han et al.,2015),一种成熟的修剪方法,即使具有相对较低的稀疏性水平,在llm上也会显著失败
- 一旦llm达到一定规模(实际中约6B参数),一小组隐藏状态特征就会比其余特征大得多。这些离群值特征表现出几个有趣的特征。首先,它们有非常大的大小,大约是典型的隐藏状态值的100倍。其次,它们通常是稀疏的,并且存在于某些特定的特征维度中。最后,这些离群值特征对于llm的预测能力是至关重要的:在推理时消除这些特征将导致语言建模性能的显著下降
- 与SparseGPT不同,我们的方法不需要对修剪过的网络进行权值更新,这表明llm具有有效的精确的稀疏子网络,而不是它们仅仅存在于原始权值的邻域中
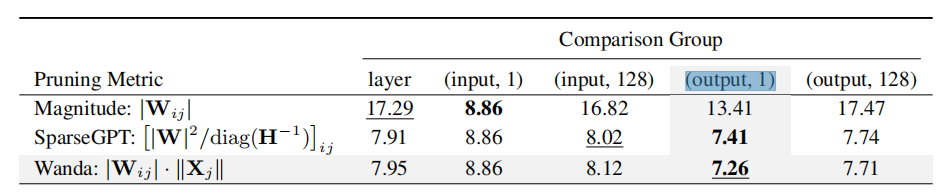
- 选择正确的比较组对于剪枝大型语言模型(LLMs)非常重要,即使在传统的Magnitude剪枝方法中也是如此
方法
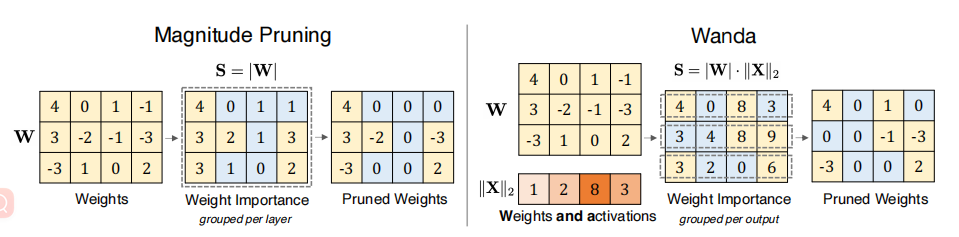
我们在每个输出的基础上(图中的每一行)上比较和删除权重,其中权重重要性分数在每个输出神经元中进行局部比较
对比SparseGPT:
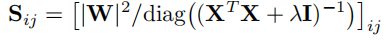
令$\lambda=0$:
实验
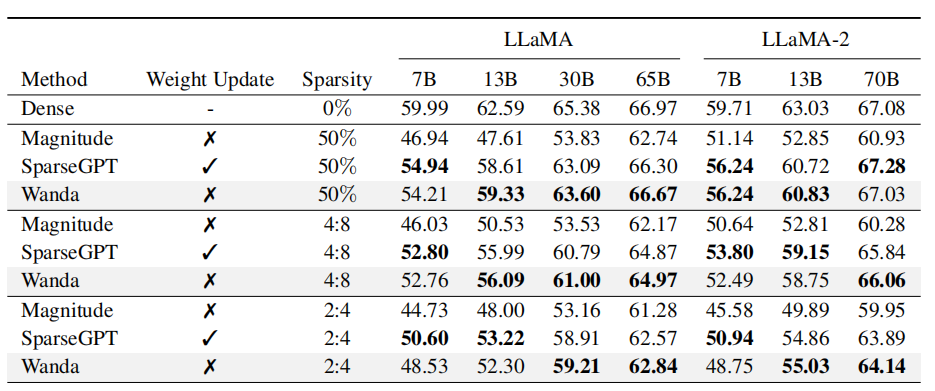
校准数据量:
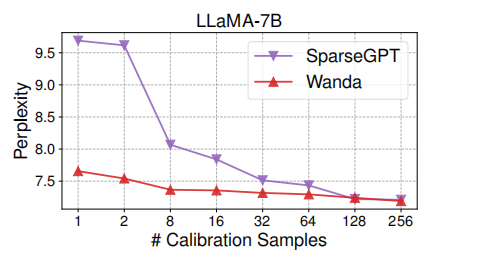
不同分组结果:
18 SparseBERT
简介
| 名称 | Rethinking Network Pruning— under the Pre-train and Fine-tune Paradigm |
|---|---|
| 期刊 | |
| 发表时间 | 2021 |
| 代码 | https://github.com/dongkuanx27/SparseBERT |
| 压缩技术 | SparseBERT将在微调阶段执行。它在修剪的同时保留了通用的和特定于任务的语言知识、幅度剪枝 |
笔记
- 通过研究知识在训练前、微调和修剪过程中如何传递和丢失来填补这一空白,并提出一个知识感知的稀疏剪枝过程
- 最近的研究结果表明,自我注意和前馈层是过度参数化的,是最多计算消耗的部分
方法
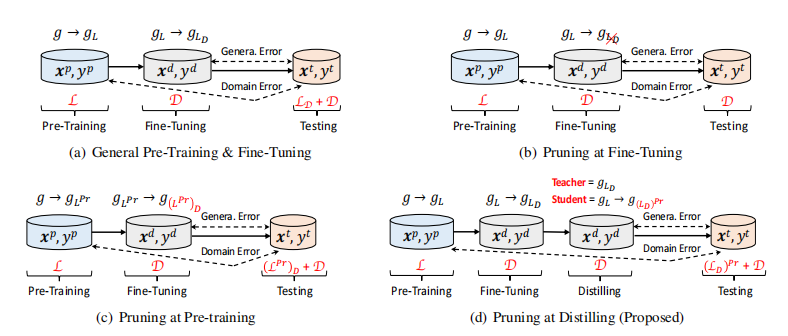

SparseBERT使用没有微调的预先训练的BERT作为初始化模型,修剪自注意和前馈层的线性变换.
为了在剪枝过程中学习特定于任务的任务知识,同时保留通用知识,我们应用了知识蒸馏:采用特定任务的微调BERT作为教师网络,采用预先训练的BERT作为学生。我们将下游任务数据输入师生框架,以训练学生再现教师的行为。
蒸馏损失:
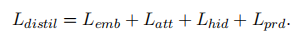
蒸馏与剪枝并行:
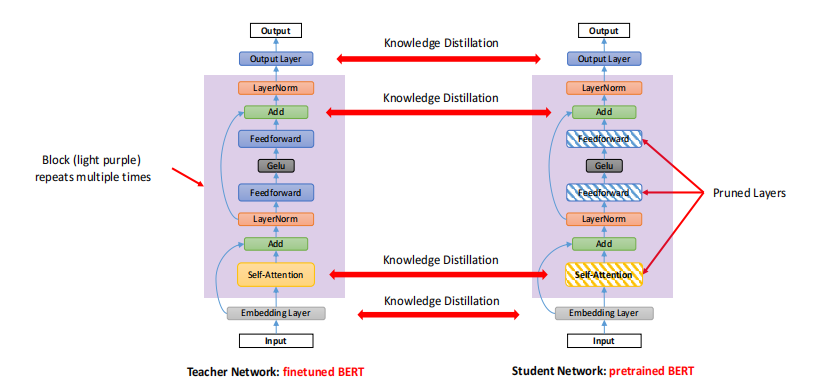
实验
19 Compresso
简介
| 名称 | Compresso: Structured Pruning with Collaborative Prompting Learns Compact Large Language Models. |
|---|---|
| 期刊 | |
| 发表时间 | 2023 |
| 代码 | (https://github.com/microsoft/Moonlit/tree/main/Compresso) |
| 压缩技术 | 使用指令调优数据集、提示词、端到端剪枝 |
笔记
- LLM培训由于其庞大的模型规模,资源非常密集。其次,llm的训练数据集是广泛的,而且由于法律限制,往往不可用。直接使用开源数据集可能会导致分布外的问题,因为剪枝数据的分布与预训练前的数据分布有很大的不同
- 大多数最先进的修剪方法都涉及到一个训练过程来更新梯度,并利用它们来估计权重的重要性,然而,由于两个主要原因,这些方法不能直接应用于llm。首先,它们是需要下游训练数据集。因此,修剪后的模型不能保留在不同任务之间的泛化能力。其次,llm的修剪过程需要大量的训练资源。
- 尽管它的速度很快,但一次性修剪也有其局限性。首先,它在很大程度上依赖于预先预定义的权重重要性度量来修剪决策,因此在所有层之间采用均匀稀疏比,而不考虑每个层的不同冗余。其次,与基于训练的剪枝相比,剩余模型参数的误差恢复很有限,这可能会影响最终的性能。我们的压缩机解决了所有这些限制。
- 使用指令对llm进行微调已被证明可以提高性能和对不可见任务的泛化
方法
为了解决基于训练的剪枝中高训练成本和数据收集的挑战,我们将低秩适应(LoRA)纳入L0正则化,并使用指令调优数据集作为训练数据的替代方案。具体来说,我们利用可学习的二进制掩码来决定是否保留或修剪每个子模块(即,头、FFN中间维度和隐藏维度)。
然后,在指令调整过程中,采用L0正则化方法优化掩模值,同时通过LoRA更新模型参数。此外,与一次性LLM修剪方法相比,通常采用跨所有层的均匀稀疏比,压缩机自动学习改进的层级稀疏比。
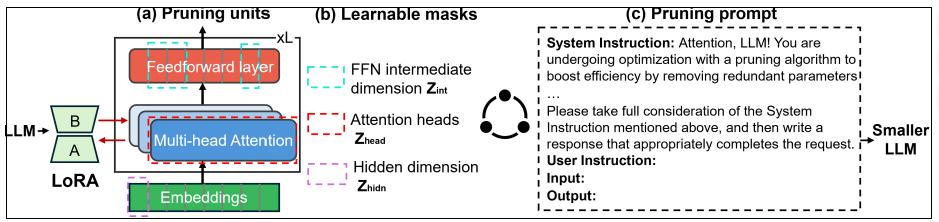
数据集:建议使用指令调优数据集作为修剪数据。尽管它们的分布不同于训练前的数据集,但它们已经证明了在微调预训练和收敛的llm以符合人类意图方面的成功
高效的基于训练的结构化修剪:
基本思想是: (i)我们引入一组二进制掩模Z∈{0,1}来指示是删除(Z = 0)还是保留(Z = 1)每个掩模子模块,从而表示剩余的模型大小;(ii)我们冻结原始LLM,利用LoRA向LLM的秩分解矩阵注入LLM可训练的每一层。这大大减少了可训练参数的数量和所需的GPU内存;(iii)我们使用增强的L0正则化联合优化这些掩模值和LoRA模块(方法。这确保了修剪后的模型大小满足给定的约束条件。
剪枝形式(采用Cofi):
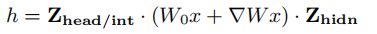
引入Lora:
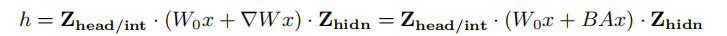
定义稀疏性函数(无需手动选择剪枝比例):
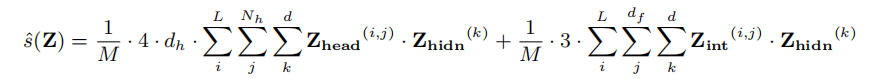
$L_0$重参数化:
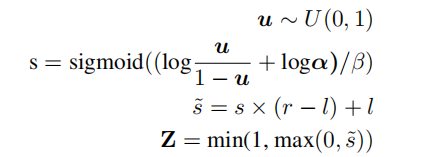
惩罚项:
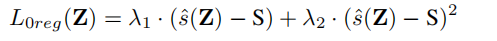
训练目标是下一个令牌预测损失和$L_{0{reg}}$损失的组合。
剪枝过程中,我们将提示符放在输入文本之前。根据指令调优的实践(Taori et al.,2023),我们不计算提示部分的下一代令牌生成损失。协作提示在两个阶段的修剪和推理阶段都被使用:

实验
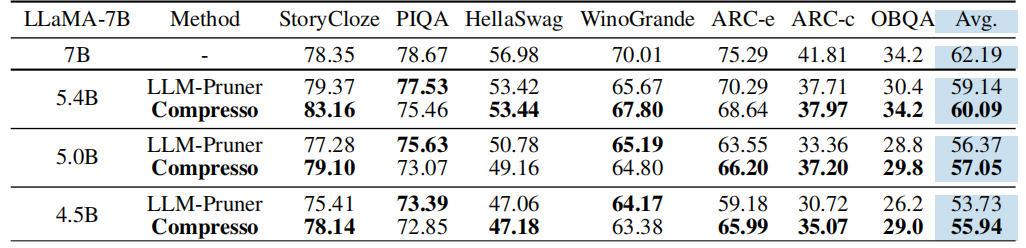
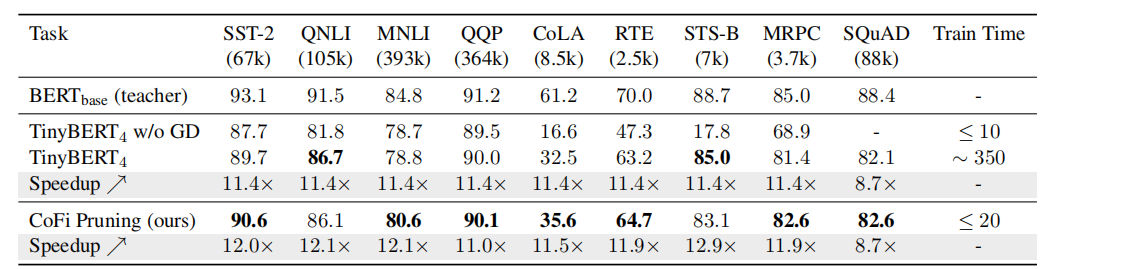
20 Cofi
简介
| 名称 | Structured Pruning Learns Compact and Accurate Models |
|---|---|
| 期刊 | ACL |
| 发表时间 | 2022 |
| 代码 | https://github.com/princeton-nlp/CoFiPruning |
| 压缩技术 | 粗粒度和细粒度剪枝、分层精馏策略 |
笔记
- 蒸馏方法需要大量的未标记数据,而且训练成本昂贵
- 经验证据表明,50%的层可以下降,而没有很大的精度下降,导致2×的加速。
- FFN修剪的其他主要部分-前馈层(FFNs)-也被认为是过度参数化的
- 加速率是我们在整个论文中使用的一个主要度量方法,因为压缩率并不一定反映了推理延迟的实际改进
- 我们将这项工作的范围框架为针对特定任务的剪枝。我们希望未来的研究能够继续这一工作,因为与一般蒸馏相比,从大型预训练模型进行的修剪可能会导致更少的计算,并导致更灵活的模型结构
方法
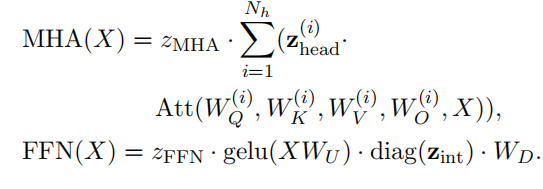
目标稀疏:
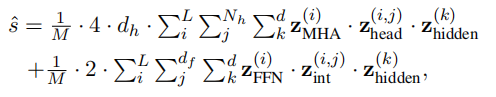
隐层蒸馏损失:
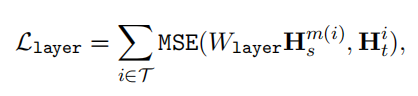
动态映射关系:
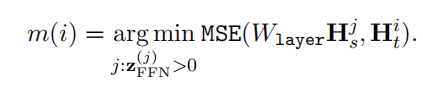
蒸馏损失:
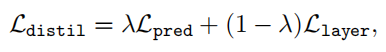
实验
21 BIP
简介
| 名称 | Advancing Model Pruning via Bi-level Optimization |
|---|---|
| 期刊 | NeurIPS |
| 发表时间 | 2022 |
| 代码 | https://github.com/OPTML-Group/BiP |
| 压缩技术 | 剪枝-训练范式并行处理,双层优化 |
笔记
- 正如彩票假说(LTH)所示,修剪也有提高其泛化能力的潜力
- 获得较高的剪枝模型精度(如IMP)和较高的计算效率(如一次性剪枝)
- 剪枝-再训练学习范式涵盖了两种任务:❶剪枝决定了模型权值的稀疏模式,以及❷训练保留非零权值来恢复模型的精度
- 底层和上层优化的数据批量选择:我们在实现(θ-step)和(m-step)时,采用不同的数据批量(具有相同的批量大小)。这是BLO公式的优点之一,它可以灵活地定制底层和上层问题
- 在m上的离散优化:我们遵循“凸松弛+硬阈值”机制。具体地说,我们将二进制掩蔽变量放宽为连续掩蔽分数m∈[0,1]。然后我们得到基于松弛m的后传递损失梯度
方法
将剪枝任务(即❶)和模型再训练任务(即❷)解释为两个优化级别,其中前者被表述为上层优化问题,并依赖于低层次再训练任务的优化。因此,我们将模型剪枝问题转换为以下BLO问题(❷嵌套在❶中):
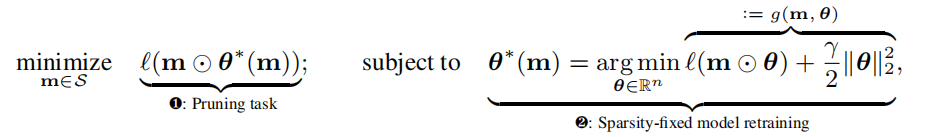
BLO可以灵活地在上层和下层的优化级别上分别使用不匹配的修剪和再训练目标。这种灵活性允许我们在(1)中规范底层训练目标函数,并在两个级别上定制已实现的优化方法。更具体地说,我们可以使用一个数据批处理(称为B2)来更新上层修剪掩码m,而不是不同于用于获取底层解决方案θ∗(m)的数据批处理(称为B1)。由此产生的BLO过程可以模拟元学习的想法来改进模型泛化[98],其中低级问题使用B1对θ进行微调,而上层问题使用B2验证稀疏感知精细模型(m⊙θ∗(m))的泛化。
在梯度下降的情况下,公式中的目标函数的梯度产生:
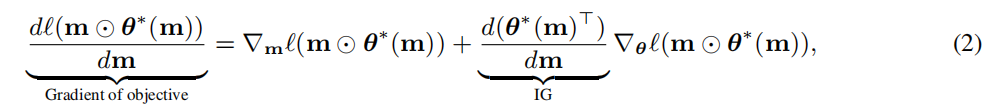
IG:
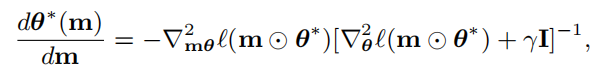
由于矩阵反演和二阶偏导数的存在,精确的IG公式(3)仍然难以计算。为了简化它,我们施加了无黑森假设,∇2θℓ=0,它一般是温和的
近似:
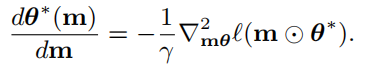
使用一阶近似:
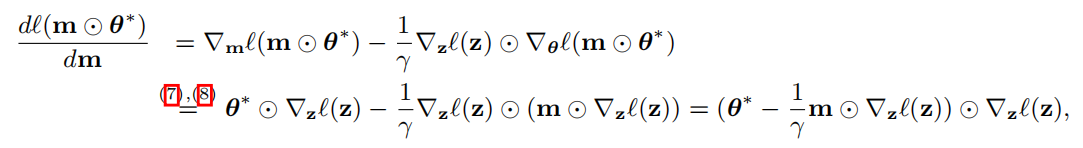
两个步骤:
用于模型再训练的较低级别的SGD:
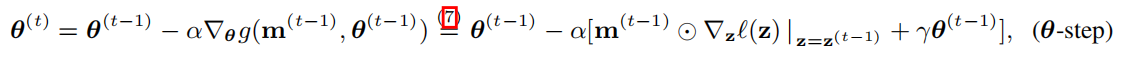
用于修剪的上层SPGD:
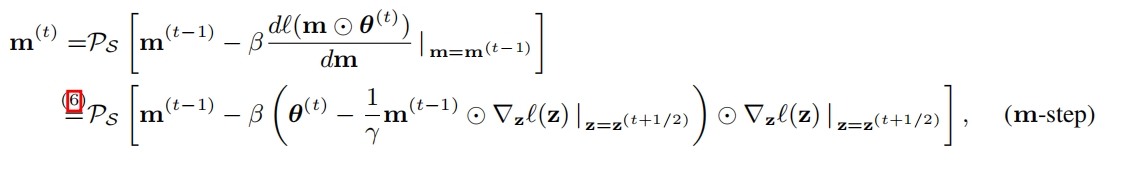
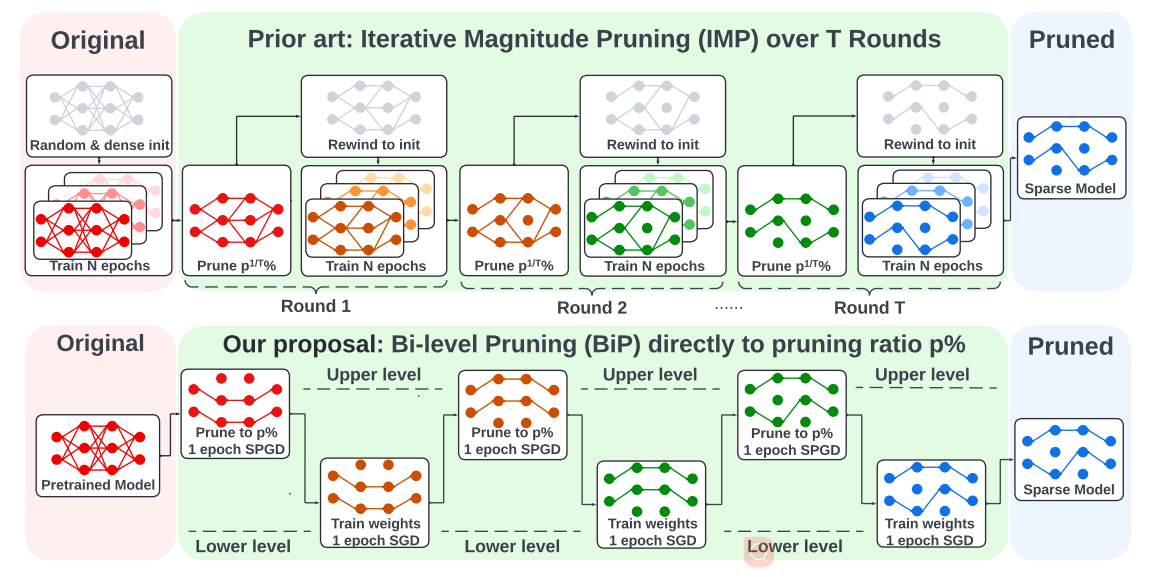
实验

22 Compress,Then Prompt
简介
| 名称 | Compress, Then Prompt: Improving Accuracy-Efficiency Trade-off of LLM Inference with Transferable Prompt |
|---|---|
| 期刊 | |
| 发表时间 | 2023 |
| 代码 | |
| 压缩技术 | 提示剪枝 |
笔记
- 引入了一个新的视角,通过提示压缩模型来优化这种权衡。具体来说,我们首先观察到,对于某些问题,通过添加精心设计的硬提示,可以显著提高压缩LLM的生成质量
- 最近的一项研究调查了OPT-175B模型的推理过程,发现(1)令牌生成是导致推理延迟的主要因素,(2)多层感知器(MLP)在令牌生成过程中比注意块产生更高的I/O和计算延迟
- 设计提示的成功意味着三个巨大的潜力:
- 跨数据集可移植性。这个人为设计的提示只提供了模型重量不准确的信息。因此,直观地说,不管使用的特定数据集,我们假设llm可以在相同的提示下生成更相关的响应。
- 交叉压缩的可转移性。类似地,人工设计的提示符只提到权重不准确,而没有指定确切的压缩级别或方法。我们假设llm可以在不同的压缩级别和方法中以相同的提示生成更多相关的响应
- 跨任务可转移性。如果llm能够理解它们的压缩状态并相应地进行调整,那么这种适应性并不局限于特定的任务或问题领域。相反,它可以扩展到广泛的任务
方法
数据驱动的方法来学习软提示:
剪枝之后,目标函数:
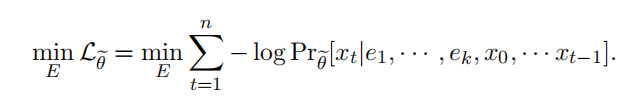
不更新模型参数:需要注意的是,压缩后的模型参数是固定的,不会被更新。唯一可训练的参数是提示标记的嵌入,它们由矩阵E表示,大小为k×d.初始化提示标记嵌入:提示标记的嵌入矩阵E的初始化采用了一种方法,其中每行的向量都是从LLM的标记嵌入矩阵W中随机选择的。
实验
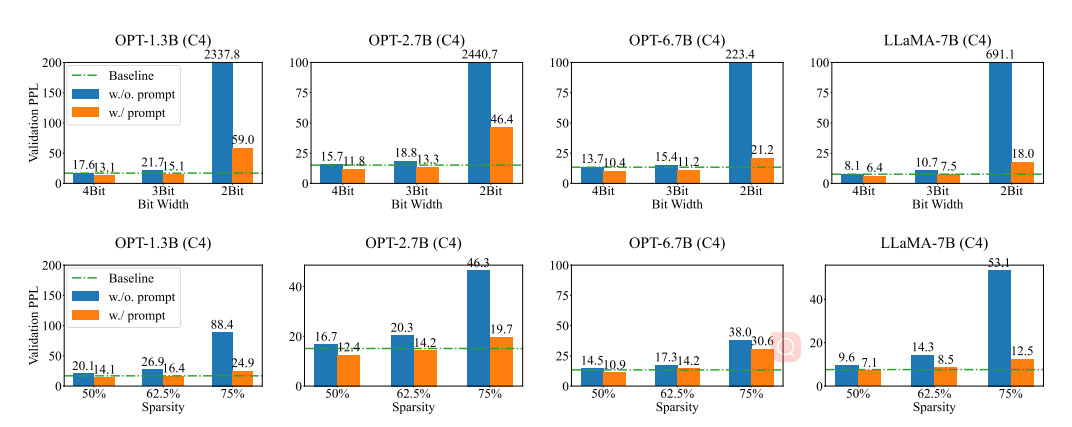
23 SPARSEGPT
简介
| 名称 | SPARSEGPT: MASSIVE LANGUAGE MODELS CAN BE ACCURATELY PRUNED IN ONE-SHOT |
|---|---|
| 期刊 | ICML |
| 发表时间 | 2023 |
| 代码 | https://github.com/ist-daslab/sparsegpt |
| 压缩技术 | 非结构剪枝 |
笔记
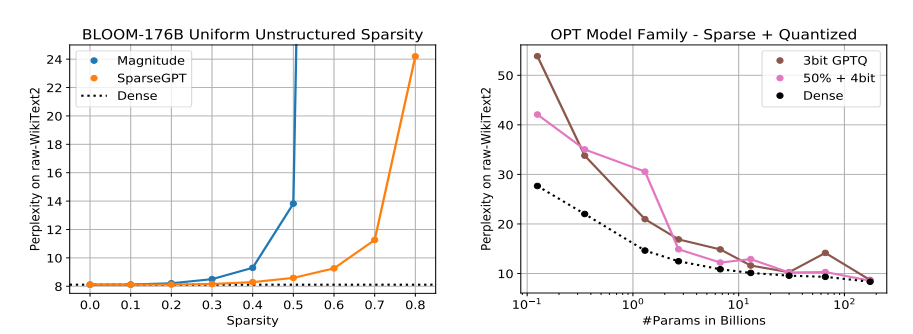
- 大规模生成式预训练变压器(GPT)家族模型可以在一次射击中修剪到至少50%的稀疏性,而不需要任何再训练,以最小的精度损失
- 我们的方法完全是局部的,在某种意义上,它仅仅依赖于权重更新,旨在保持每一层的输入-输出关系,这些计算没有任何全局梯度信息。因此,值得注意的是,人们可以在密集预训练模型的“邻域”中直接识别这种稀疏模型,其输出与密集模型的输出非常密切相关
- 较大的模型更容易稀疏:具体地说,我们发现,对于一个固定的稀疏水平,相对精度差距的密集和稀疏模型变体缩小我们增加模型大小,诱导50%稀疏性导致几乎没有精度减少最大的模型
- 一种特别流行的方法是将该问题划分为掩模选择和权重重建[20,27,22]。具体地说,这意味着首先根据一些显著性准则选择一个修剪掩模M,如权值大小[50],然后在保持掩模不变的同时优化剩余的未修剪权值
- 在每个剪枝步骤之后,它执行权重更新,旨在保留每个层的输入-输出关系。这些更新的计算没有任何全局梯度信息。因此,大规模GPT模型的高度参数化使得我们的方法能够直接识别密集预训练模型的“近邻”中的稀疏精确模型。值得注意的是,由于我们的主要精度度量(困惑度)是非常敏感的,因此生成的稀疏模型的输出似乎与密集模型的输出非常密切相关。我们的第二个主要发现是,较大的模型更容易稀疏:在一个固定的稀疏水平,稀疏模型的相对精度下降,相对于密集的,缩小我们增加模型大小,诱导50%稀疏导致几乎没有精度减少最大的模型。这一发现应该被视为对未来压缩如此大规模的模型的工作非常令人鼓舞。
方法
掩码的选择和权重的重建:
种特别流行的方法是将该问题划分为掩模选择和权重重建[20,27,22]。具体地说,这意味着首先根据一些显著性准则选择一个剪枝掩模M,如权值大小[50],然后在保持掩模不变的同时优化剩余的未剪枝权值。重要的是,一旦掩模固定,(2)就变成一个线性平方误差问题,它是凸的,因此很容易优化。甚至可以通过对每个矩阵行应用标准的线性回归公式,以封闭的形式求解:
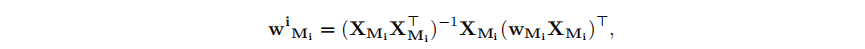
标准线性回归的方程通常表示为:
Y = X * β + ε
其中:
- Y 代表因变量(目标)。
- X 代表自变量(输入特征)。
- β 代表回归系数,它是一个向量,包含了每个输入特征的权重。
- ε 代表误差项,表示模型无法完美拟合数据的部分。
标准线性回归的目标是找到最佳的回归系数β,以使误差项ε的平方和最小化,通常通过最小二乘法(Least Squares)来实现。
封闭形式解是指可以通过数学公式直接求解得到的解。对于标准线性回归,封闭形式解是:
β = (X^T X)^(-1) X^T * Y
更新权重:

每列迭代更新:
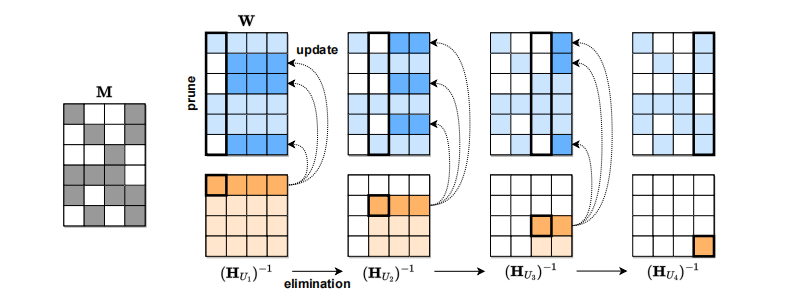
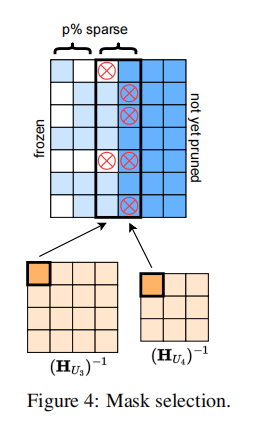
根据误差自适应选择掩码:

实验
24 OCB
简介
| 名称 | Optimal Brain Compression: A Framework for Accurate Post-Training Quantization and Pruning |
|---|---|
| 期刊 | NeurIPS |
| 发表时间 | 2022 |
| 代码 | https://github.com/ist-daslab/obc |
| 压缩技术 | 非结构剪枝、局部剪枝 |
笔记
- 我们给定了一个精确的训练模型,并且必须在没有任何再训练的情况下压缩它,仅基于少量的校准输入数据
- OBS可以在DNN尺度上导致最先进的压缩,通过引入数值方法,可以近似OBS在现代模型的大量参数计数上所需的二阶信息。然而,这些方法并不适用于训练后的设置,因为它们需要逐步修剪,以及显著的再训练,以恢复良好的准确性。
- AdaRound、AdaQuant和BRECQ的一个关键步骤是按顺序逐步量化层,这样在早期层中积累的误差就可以通过在后期层中的权重调整来补偿
方法
剪枝目标:
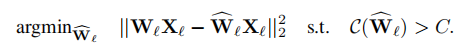
OBS:
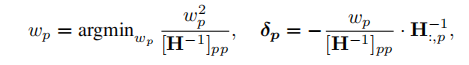
处理单行:
使用高斯分解,迭代海森逆矩阵:
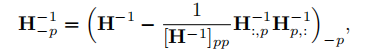
根据剪枝目标函数快速求出权重的海森矩阵:
在标准的线性回归问题中,目标函数为:
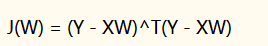

所有行处理:
依次计算每个loss,从而计算全局掩码,之后再进行更新。两种方案:
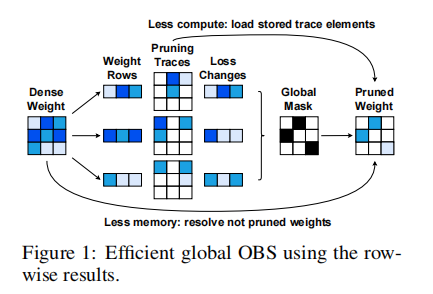
实验
25 AdaPrune
简介
| 名称 | Accelerated Sparse Neural Training: A Provable and Efficient Method to Find N:M Transposable Masks NeurIPS |
|---|---|
| 期刊 | NeurIPS |
| 发表时间 | 2021 |
| 代码 | https://github.com/papers-submission/structured_transposable_masks |
| 压缩技术 | 幅度剪枝、半结构化 |
笔记
- 由于弗兰克尔和Carbin [12]通过应用密集训练发现了最佳面具(中奖彩票),所以如何在没有训练的情况下找到最佳面具的问题仍然悬而未决
方法
MD:(越大越好)
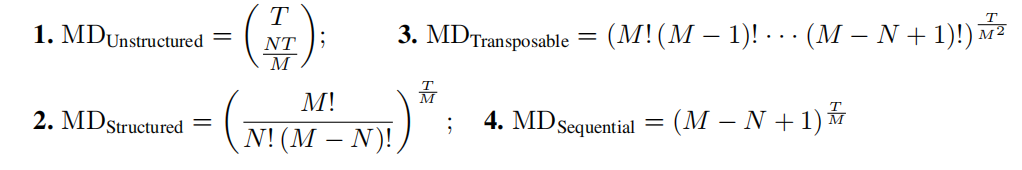
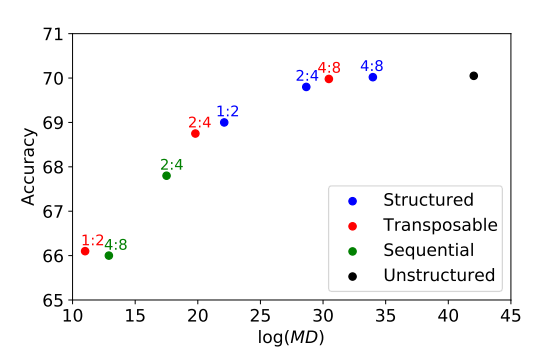
转置掩码目标函数:
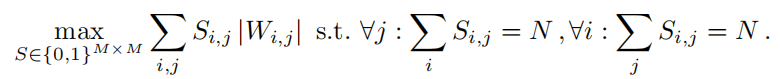
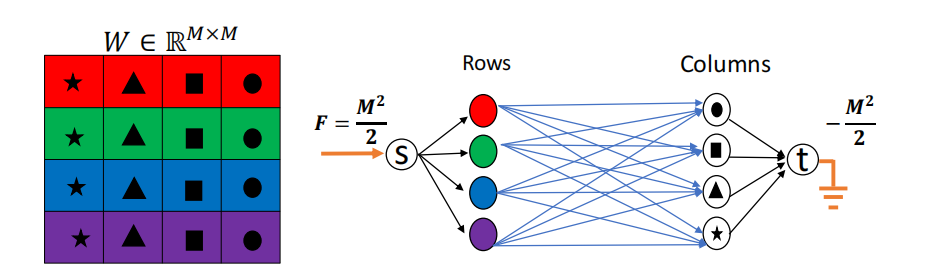
转变为最小流问题:
进一步近似算法:

4:8转到2:4,全量微调,1000K校正数据
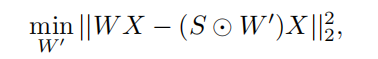
实验
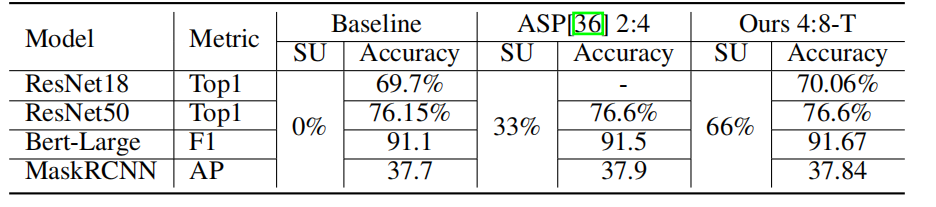
26 Post training 4-bit quantization
简介
| 名称 | Post training 4-bit quantization of convolutional networks for rapid-deployment |
|---|---|
| 期刊 | NeurIPS |
| 发表时间 | 2019 |
| 代码 | https://github.com/submission2019/cnn-quantization |
| 压缩技术 | 四位量化 |
笔记
- 本文介绍了第一种实用的4位训练后量化方法:它不涉及量化模型的训练(微调),也不需要完整数据集的可用性。
- 训练是补偿量化导致的模型精度损失的有效方法。然而,它并不总是适用于现实世界的场景,因为它需要全尺寸的数据集,而由于隐私、专有或使用现成的预先训练的模型,数据通常无法访问。培训也很耗时,需要很长时间的优化,以及熟练的人力和计算资源。
方法
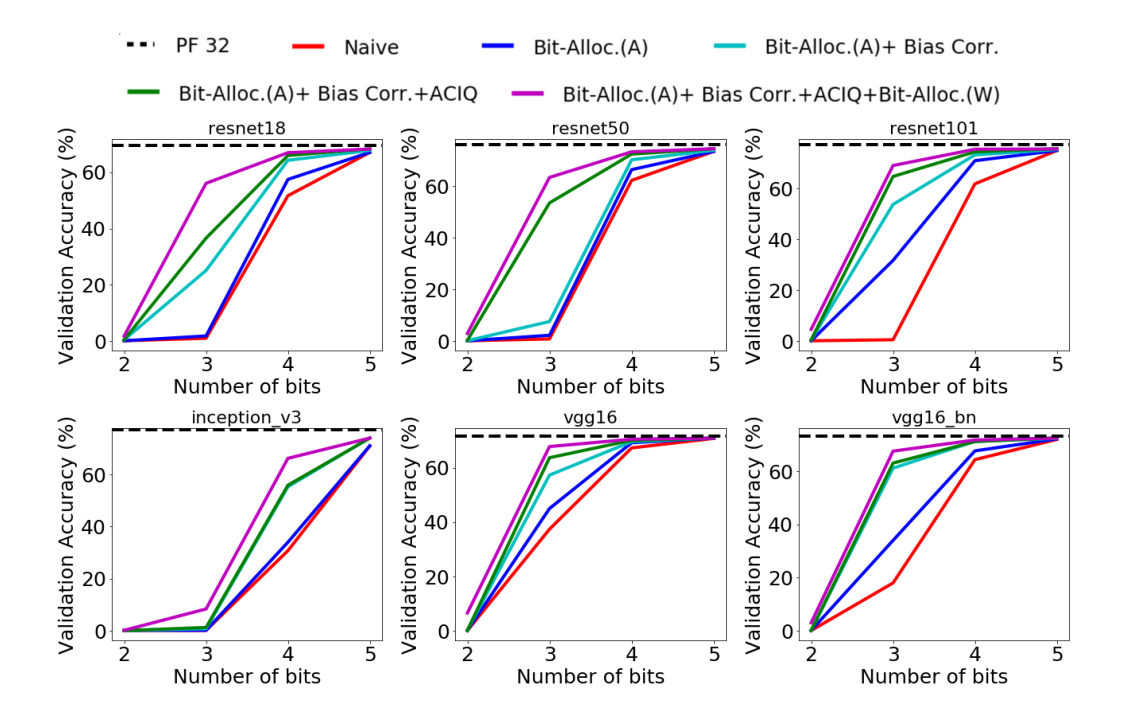
ACIQ: Analytical Clipping for Integer Quantization:
通常,整数张量在张量的最大值和最小值之间被均匀地量化。在下面,我们证明了这是次优的:
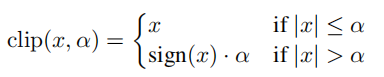
位数为M,量化值为:
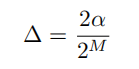
X与其量化版本Q (X)之间的期望均方误差:
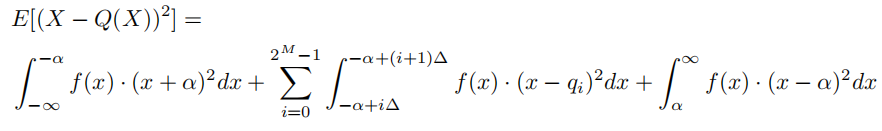
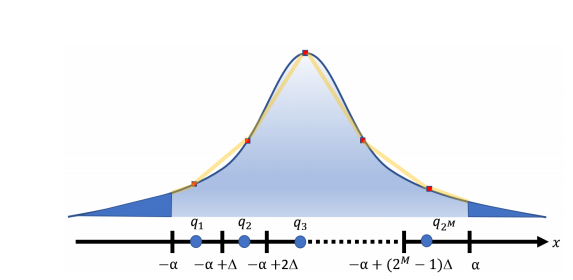
量化噪声:
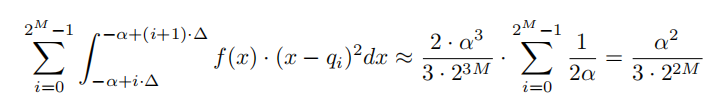
切片噪声:
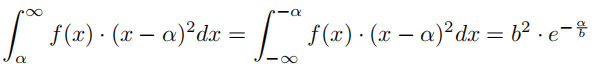
总误差:
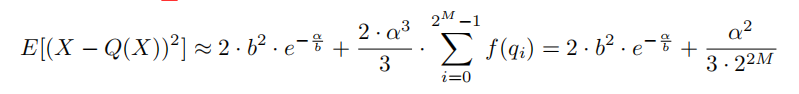
给定M情况下,求出ab关系:
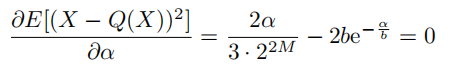
Per-channel bit-allocation:我们不是限制所有通道值具有相同的4位表示,而是允许一些通道具有更高的位宽,而限制其他通道具有更低的位宽。我们唯一的要求是,写入内存或从内存中读取的位的总数保持不变。
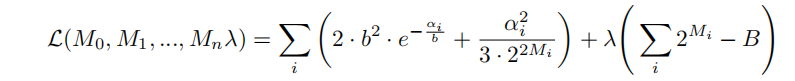
拉格朗日求解:
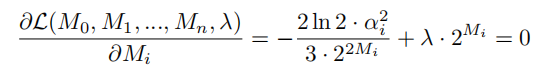
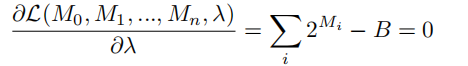
每个通道的最优解:
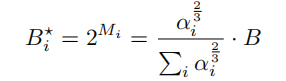
Bias-Correction:量化之后具有固有偏差,在平均值和方差存在误差:
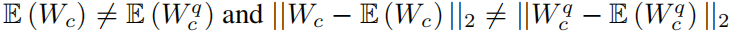
于是提出修正:
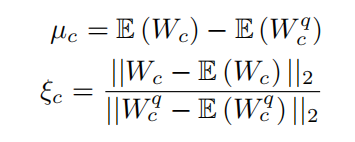
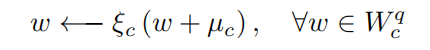
整合
Weights and Activations: 对于权重和激活值,作者采用了逐通道的位分配策略。这意味着每个通道(例如,卷积层的不同滤波器)都可以有不同的位宽,而不是整个层都使用相同的位宽。这允许网络根据每个通道的需求来分配位数,从而更灵活地进行量化。
Reasoning: 作者在权重上没有采用任何形式的剪切操作。这是因为先前的研究(如Migacz, 2017; Zhao et al., 2019)已经指出,在较大的位宽情况下,即使用较多的位数表示权重时,采用权重剪切并没有明显的优势。
Weights vs. Activations: 作者在量化激活值时采用了ACIQ(Analytical Clipping for Integer Quantization)方法,但没有在权重上使用它。这可能是因为先前的研究或实验证据表明,在某些情况下,对激活值应用剪切可以更有效地减小量化引入的误差,而在权重上使用可能没有相同的优势
仅对权重进行偏差校正(Bias Correction for Weights Only):
Offline vs. Online Bias Correction: 作者提到偏差校正(Bias Correction)的方法可以应用于权重和激活,但由于权重的偏差可以在离线情况下进行,而激活的偏差需要通过运行输入图像进行估计,因此只对权重进行了偏差校正。在线估计激活偏差可能会在运行时引入较大的计算开销。
实验
27 GPTQ
简介
| 名称 | GPTQ: ACCURATE POST-TRAINING QUANTIZATION FOR GENERATIVE PRE-TRAINED TRANSFORMERS |
|---|---|
| 期刊 | ICLR |
| 发表时间 | 2023 |
| 代码 | https://github.com/IST-DASLab/gptq |
| 压缩技术 | 二阶近似量化 |
笔记
- OBQ以贪婪的顺序量化权值,即它总是选择当前导致的附加量化误差最小的权值。有趣的是,我们发现,虽然这种相当自然的策略似乎确实表现得很好,但它比以任意顺序量化权重的改进通常很小,特别是在大的、高度参数化的层上。最有可能的情况是,这是因为具有较小的量化权值数量被过程结束时被量化的权值所平衡,此时只剩下少数其他可以为补偿调整的未量化权值
方法
Step 1: Arbitrary Order Insight:以相同的顺序量化所有行的权值
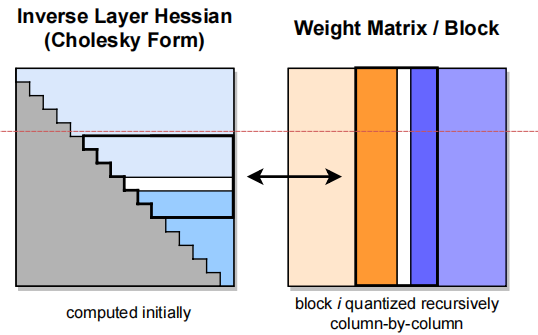
Step 2: Lazy Batch-Updates:只有一次块已经完全处理,我们执行全局更新整个H−1和W矩阵使用多权重版本的方程(2)和(3)如下:
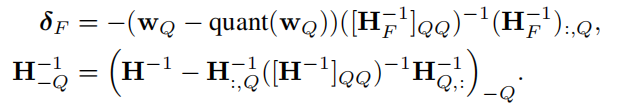
Step 3: Cholesky Reformulation
整体算法:

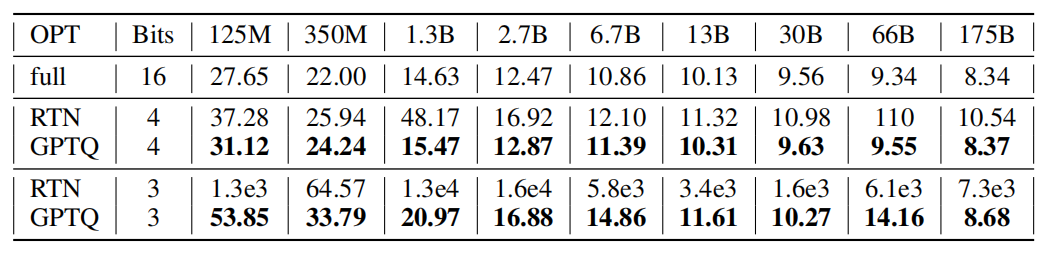
实验
28
简介
| 名称 | Improving Neural Network Quantization without Retraining using Outlier Channel Splitting |
|---|---|
| 期刊 | ICML |
| 发表时间 | 2019 |
| 代码 | https://github.com/cornell-zhang/dnn-quant-ocs |
| 压缩技术 | 识别少量包含异常值的通道,复制它们,然后将这些通道中的值减半 |
笔记
- 在训练深度神经网络(DNN)之后,网络的权重和激活值通常会呈现出钟形分布的特征而实际硬件在进行量化时使用线性量化网格,这意味着硬件会将连续的范围划分成等间隔的线性步长,将浮点数值映射到离散的量化级别。这样的线性量化网格可以简化硬件实现,但也带来了一个问题,即分布的形状与线性量化网格之间可能存在不匹配,导致一些数值落在量化级别之外,称为异常值。
方法
分割通道,将值变小之后再量化:
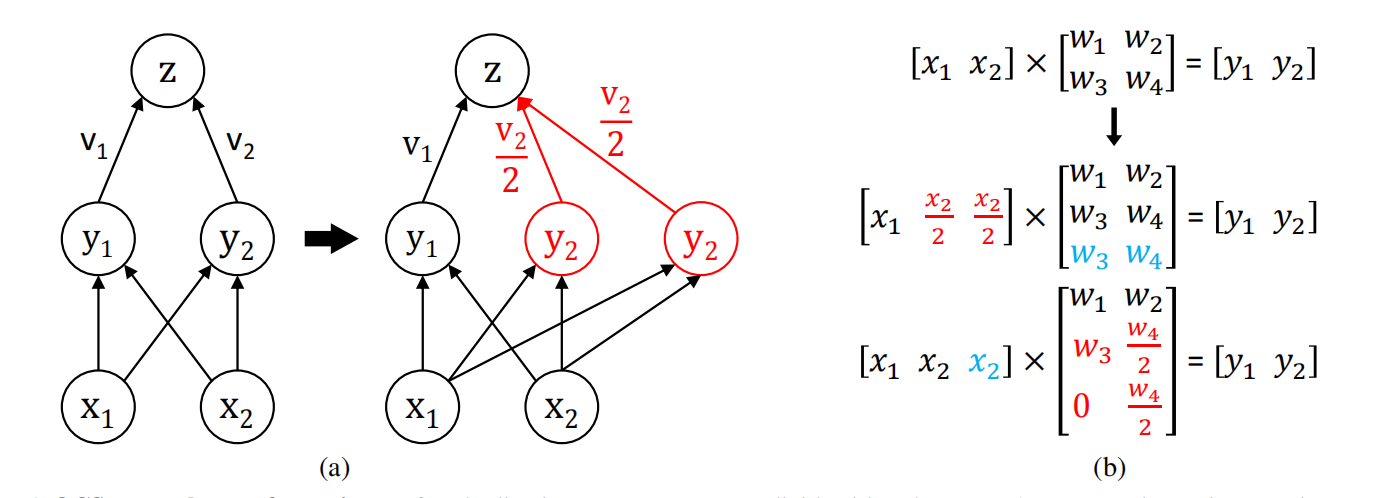
分裂量化:
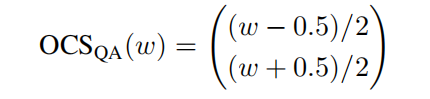
实现了无差量化:
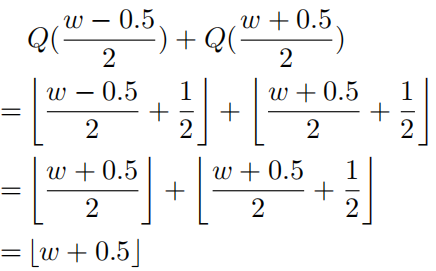
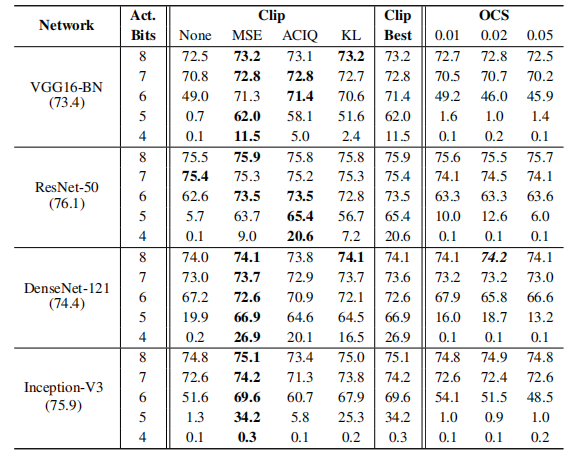
实验
29AWQ
简介
| 名称 | AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration |
|---|---|
| 期刊 | |
| 发表时间 | 2023 |
| 代码 | https://github.com/mit-han-lab/llm-awq |
| 压缩技术 | 训练后量化,激活异常值感知 |
笔记
- GPTQ可能会在重建过程中过度拟合校准集,使分布外域上的学习特征发生扭曲,这可能会有问题,因为llm是多面体模型。
- 为了找到显著的权重通道,我们应该参考激活分布而不是权重分布,尽管我们只做权重量化
- 为了避免硬件效率低下的混合精度实现,我们分析了权重量化的误差,并推导出放大显著通道可以减少它们的相对量化误差。
- 局限性:尽管在FP16中保留0.1%的权重可以提高量化性能,而不显著增加模型大小(以总位测量),这种混合精度数据类型将使系统实现变得困难。我们需要提出一种方法来保护重要的重量,而不实际保留它们作为FP16。
方法
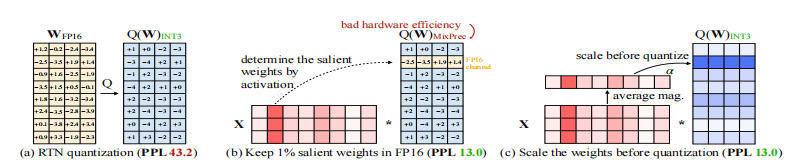
原量化:
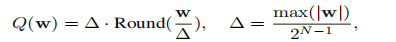
缩放:

目标函数:
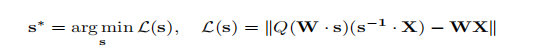
网格搜索:
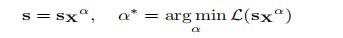
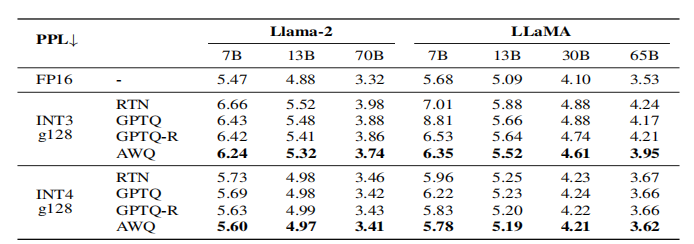
实验
30AdaRound
简介
| 名称 | Up or Down? Adaptive Rounding for Post-Training Quantization |
|---|---|
| 期刊 | ICML |
| 发表时间 | 2020 |
| 代码 | |
| 压缩技术 | 训练后量化,非四舍五入近似 |
笔记
- 四舍五入量化次优
方法
约束量化范围:
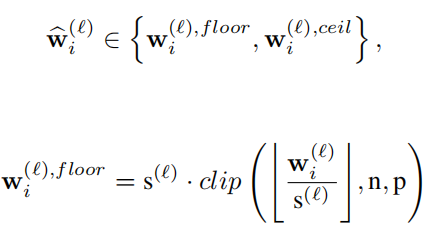
目标函数:
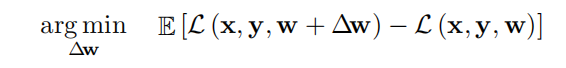
二阶近似:
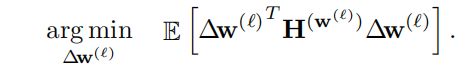
对角假设和常数假设:
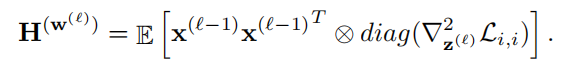
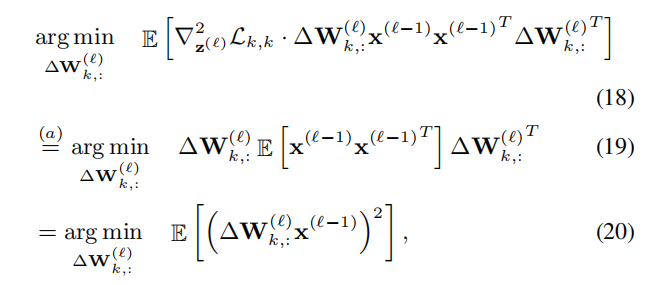
松弛:
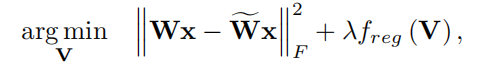
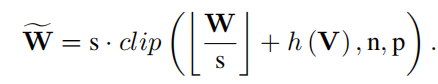
为了避免更深层次网络的量化误差的积累,并考虑到激活函数,我们使用了以下非对称重构公式:
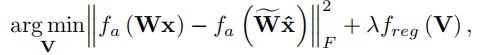
实验
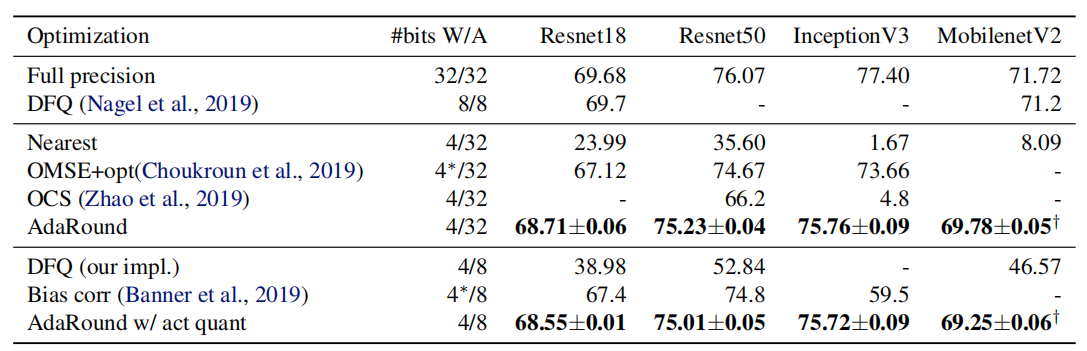
31SPDY
简介
| 名称 | SPDY: Accurate Pruning with Speedup Guarantees |
|---|---|
| 期刊 | ICML |
| 发表时间 | 2022 |
| 代码 | https://github.com/IST-DASLab/spdy |
| 压缩技术 | 非结构加速,针对推理速度 |
笔记
- 大多数现有的修剪方法只最小化剩余权值的数量,即模型的大小,而不是对推理时间进行优化。
- 我们首先观察到已知的度量,例如(标准化)权重大小,与得到的非结构化稀疏模型的优越精度不一致相关。
- 简单地用随机掩模施加相应的稀疏性,准确地估计这种稀疏性轮廓的运行时间
- 针对神经网络剪枝所导致的层次稀疏性的问题,无结构的加速技术并不依赖于在神经网络层中出现的特定模式。具体而言,即使在同一层次和相同稀疏度水平的情况下,无结构的加速技术也能够表现出相似的性能水平。这表明,该加速技术对于不同层次和不同剪枝策略都能够保持一致的效果,而不受到层次稀疏性中特定模式的影响。这种特性使得无结构的加速技术更具灵活性,能够适用于多种剪枝方法,而不受到这些方法所产生的特定稀疏模式的制约。
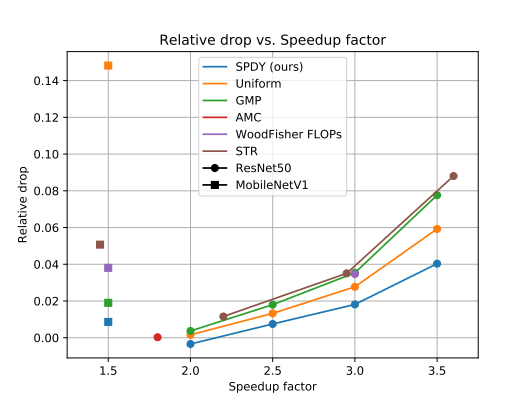
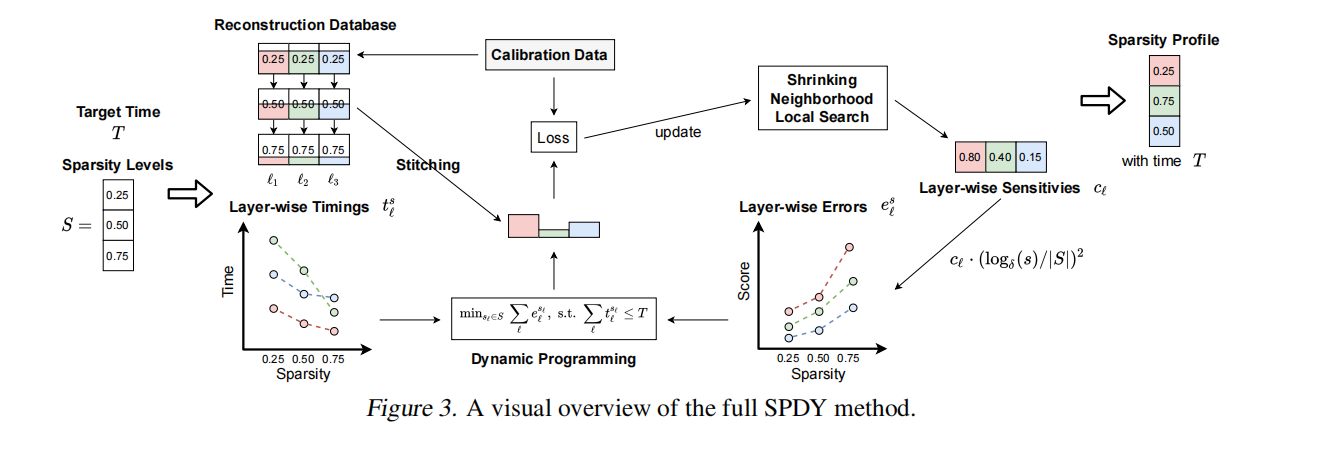
方法
约束优化公式:
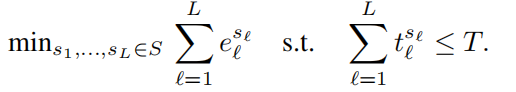
递归公式:
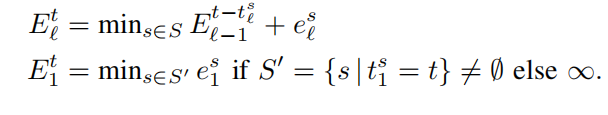
计算误差:
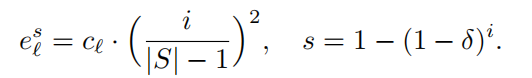
步骤i:随机选100个$c$向量,找到最好的$c^*$.评估配置的质量:
该数据库为每个层ℓ和每个稀疏度s存储稀疏度s通过AdaPrune施加后剩余权重的“重建”。
首先,我们在数据库中查询每一层对应的重构权值,每一层在其目标稀疏度处。其次,我们将重建权重的结果模型“缝合”在一起,并在给定的小验证集上对其进行评估。
实验